- 软件开发
-
sql优化问题
sql语句性能达不到你的要求,执行效率让你忍无可忍,一般会时下面几种情况。
§ 网速不给力,不稳定。
§ 服务器内存不够,或者SQL 被分配的内存不够。
§ sql语句设计不合理
§ 没有相应的索引,索引不合理
§ 没有有效的索引视图
§ 表数据过大没有有效的分区设计
§ 数据库设计太2,存在大量的数据冗余
§ 索引列上缺少相应的统计信息,或者统计信息过期
§ ....
那么我们如何给找出来导致性能慢的的原因呢?
§ 首先你要知道是否跟sql语句有关,确保不是机器开不开机,服务器硬件配置太差,没网你说p啊
§ 接着用sql性能检测工具--sql server profiler,分析出sql慢的相关语句,就是执行时间过长,占用系统资源,cpu过多的
§ 然后是这篇文章要说的,sql优化方法跟技巧,避免一些不合理的sql语句,取暂优sql
§ 再然后判断是否使用啦,合理的统计信息。sql server中可以自动统计表中的数据分布信息,定时根据数据情况,更新统计信息,是很有必要的
§ 确认表中使用啦合理的索引
§ 数据太多的表,要分区,缩小查找范围
分析比较执行时间计划读取情况
select * from dbo.Product
执行上面语句一般情况下只给你返回结果和执行行数,那么你怎么分析呢,怎么知道你优化之后跟没有优化的区别呢。
下面给你说几种方法。
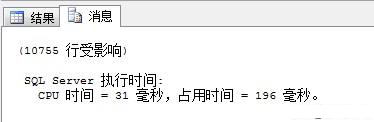
1.查看执行时间和cpu占用时间
set statistics time on
select * from dbo.Product
set statistics time off
打开你查询之后的消息里面就能看到啦。
2.查看查询对I/0的操作情况
set statistics io on
select * from dbo.Product
set statistics io off
执行之后

扫描计数:索引或表扫描次数
逻辑读取:数据缓存中读取的页数
物理读取:从磁盘中读取的页数
预读:查询过程中,从磁盘放入缓存的页数
lob逻辑读取:从数据缓存中读取,image,text,ntext或大型数据的页数
lob物理读取:从磁盘中读取,image,text,ntext或大型数据的页数
lob预读:查询过程中,从磁盘放入缓存的image,text,ntext或大型数据的页数
如果物理读取次数和预读次说比较多,可以使用索引进行优化。
如果你不想使用sql语句命令来查看这些内容,方法也是有的,哥教你更简单的。
查询--->>查询选项--->>高级
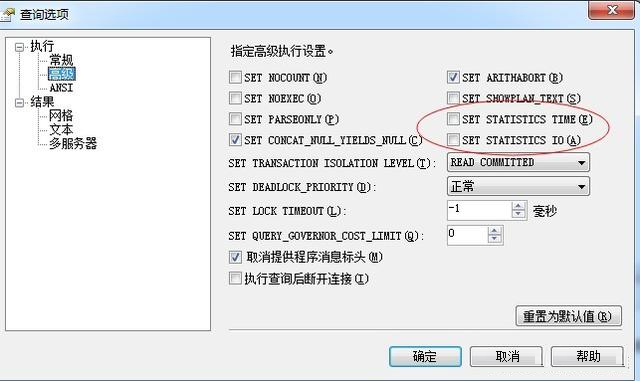
被红圈套上的2个选上,去掉sql语句中的set statistics io/time on/off 试试效果。哦也,你成功啦。。
3.查看执行计划,执行计划详解
选中查询语句,点击

然后看消息里面,会出现下面的图例
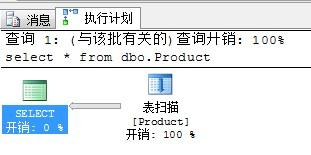
select查询艺术
1.保证不查询多余的列与行。
§ 尽量避免select * 的存在,使用具体的列代替*,避免多余的列
§ 使用where限定具体要查询的数据,避免多余的行
§ 使用top,distinct关键字减少多余重复的行
2.慎用distinct关键字
distinct在查询一个字段或者很少字段的情况下使用,会避免重复数据的出现,给查询带来优化效果。
但是查询字段很多的情况下使用,则会大大降低查询效率。
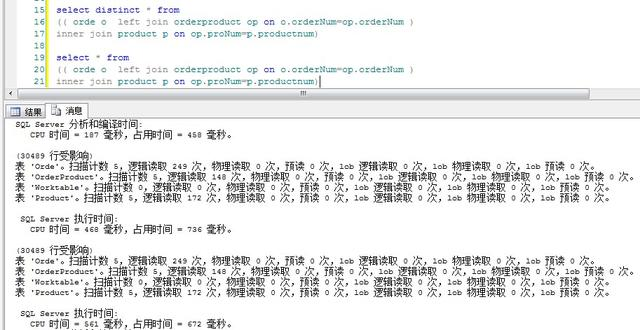
由这个图,分析下:
很明显带distinct的语句cpu时间和占用时间都高于不带distinct的语句。原因是当查询很多字段时,如果使用distinct,数据库引擎就会对数据进行比较,过滤掉重复数据,然而这个比较,过滤的过程则会毫不客气的占用系统资源,cpu时间。
3.慎用union关键字
此关键字主要功能是把各个查询语句的结果集合并到一个结果集中返回给你。用法
<select 语句1>
union
<select 语句2>
union
<select 语句3>
...
满足union的语句必须满足:1.列数相同。 2.对应列数的数据类型要保持兼容。
执行过程:
依次执行select语句-->>合并结果集--->>对结果集进行排序,过滤重复记录。
select * from
(( orde o left join orderproduct op on o.orderNum=op.orderNum )
inner join product p on op.proNum=p.productnum) where p.id<10000
union
select * from
(( orde o left join orderproduct op on o.orderNum=op.orderNum )
inner join product p on op.proNum=p.productnum) where p.id<20000 and p.id>=10000
union
select * from
(( orde o left join orderproduct op on o.orderNum=op.orderNum )
inner join product p on op.proNum=p.productnum) where p.id>20000
---这里可以写p.id>100 结果一样,因为筛选过
----------------------------------对比上下两个语句-----------------------------------------
select * from
(( orde o left join orderproduct op on o.orderNum=op.orderNum )
inner join product p on op.proNum=p.productnum)
由此可见效率确实低,所以不是在必要情况下避免使用。其实有他执行的第三部:对结果集进行排序,过滤重复记录。就能看出不是什么好鸟。然而不对结果集排序过滤,显然效率是比union高的,那么不排序过滤的关键字有吗?答,有,他是union all,使用union all能对union进行一定的优化。。
4.判断表中是否存在数据
select count(*) from product
select top(1) id from product
很显然下面完胜
5.连接查询的优化
首先你要弄明白你想要的数据是什么样子的,然后再做出决定使用哪一种连接,这很重要。
各种连接的取值大小为:
§ 内连接结果集大小取决于左右表满足条件的数量
§ 左连接取决与左表大小,右相反。
§ 完全连接和交叉连接取决与左右两个表的数据总数量
select * from
( (select * from orde where OrderId>10000) o left join orderproduct op on o.orderNum=op.orderNum )
select * from
( orde o left join orderproduct op on o.orderNum=op.orderNum )
where o.OrderId>10000
由此可见减少连接表的数据数量可以提高效率。
总结
优化,最重要的是在于你平时设计语句,数据库的习惯,方式。如果你平时不在意,汇总到一块再做优化,你就需要耐心的分析,然而分析的过程就看你的悟性,需求,知识水平啦。