



摘要
在本论文中,我们探索了最近递归神经网络用于大规模语言模型上取得的进展,主要集中于语言理解方面。我们延伸了现有的模型,处理本任务中展示的两个主要挑战:语料库和词汇量,以及语言复杂的、长期结构。我们利用「十亿单词基准」(One Billion Word Benchmark)语料库,对于一些方法进行了详尽的研究,包括针对字符的卷积神经网络,以及长短期记忆人工神经网络。我们最好的一个模型,极大地将最先进模型的 perplexity 指从 51.3 减小为 30.0(并且将参数量减少了 20 倍)。还有一个模型集成将 perplexity 值从 41.0 降低到 23.7。我们将这些模型都公开在了自然语言处理和机器学习社区上,以供他人学习的改进。
导言
语言建模(LM)对于自然语言处理和语言理解来说,是一项非常重要的任务。一个能够准确解析语句的模型,不仅仅能够编码语言的复杂性,如语法结构等,还能够提取出一个语料库可能包含的大量信息。确实如此,一个可以给句子赋值较低概率、生成较少语法错误的模型,可能在根本性的语言理解上并无帮助,例如回答问题、机器翻译、或文本摘要。
语言建模在传统的自然语言处理中曾扮演了主要的角色,如语音识别(Mikolov et al., 2010; Arisoy et al., 2012)、机器翻译(Schwenk et al., 2012; Vaswani et al.)、或者文本总结(Rush et al., 2015; Filippova et al., 2015)。通常(但并不总是),训练更好的语言模型,能够提升下游任务的基础指标(如语音识别的词错率,或 BLEU 翻译评价方法得分),而这使得训练更好的语言模型本身,成为一件十分有价值的事。
进一步来说,当在大量数据上进行训练时,语言模型能够紧密的提取训练数据中的知识编码。比如,当在电影字幕上进行训练时(Serban et al., 2015; Vinyals & Le, 2015),这些语言模型能够对关于物体颜色、角色信息等问题,提供基础的回答。最后,最近提出的「序列到序列」(sequence-to-sequence)的模型,使用了条件语言模型作为核心部件,来解决类似机器翻译(Sutskever et al., 2014; Cho et al., 2014; Kalchbrenner et al., 2014)或视频生成(Srivastava et al., 2015a)等多种任务。
深度学习和递归神经网络(RNNs)在过去几年中加速了语言建模的研究发展,因为它们使得研究人员能够在强条件独立性假设是不真实的情况下,探索多种任务。尽管更简单的模型,例如 N 元分词(N-gram),仅用很短的历史记忆来预测下一个单词,它们仍旧是高品质、低 perplexity 值的语言模型的关键组成部分。事实上,近期关于大规模语言模型的大多数研究都表明,递归神经网络在结合 N 元分词方面效果显著,因为它们的不同强项,能够很好地辅助 N 元分词模型,但是在孤立情况下的效果却要差很多(Mikolov et al., 2011; Mikolov, 2012; Chelba et al., 2013; Williams et al., 2015; Ji et al., 2015a; Shazeer et al., 2015)。
我们相信,尽管已经开展了大量针对小数据库的研究,如 Penn Tree Bank(Marcus et al., 1993),对于更大的任务的研究仍旧是十分重要的,因为过度拟合并不是当前语言建模的主要限制点,虽然它确实是 Penn Tree Bank(PTB)任务的主要特征。针对更大语料库的结果经常表明,很多构想在小数据库中效果很好,但是却很难针对大数据库进行改进。此外,考虑到当前的硬件发展趋势,以及互联网所提供的庞大文本量,先解决大范围的建模问题,是比以往都更加直接的做法。因此,我们希望我们的工作,能够帮助和激励研究人员们,投入更多精力在 PTB 之外的传统语言模型上——正因如此,我们会开源我们的模型和训练样本。
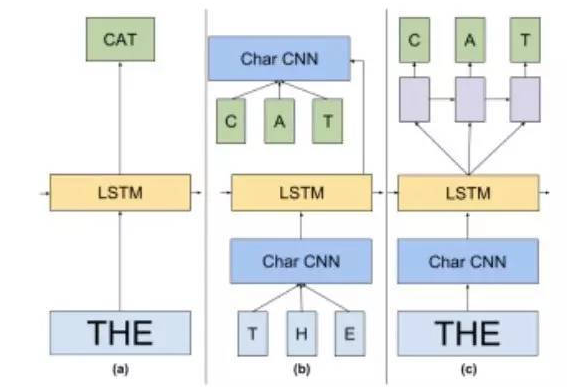
图片 1:本论文中模型的高层视图。(a)是一个标准长短词人工记忆的语言模型。(b)在这个语言模型中,输入值和 Softmax 嵌入都被替代为了字符卷积神经网络。在(c)中,我们使用预测下一字符的长短句人工记忆网络来代替 Softmax。
我们的关注点集中在一个十分有名的、大规模语言模型基准:「十亿单词基准」数据集(Chelba et al., 2013)。这个数据集比 PTB 要大许多(大一千倍,80 万词汇表和 10 亿单词训练数据),并且更加具有挑战性。与改进了计算机视觉的 Imagenet 相似(Deng et al., 2009),我们相信通过清晰地基准,来释放和研究大数据集和模型,能够帮助改进语言建模。
我们做出的贡献有:
我们研究、扩展并尝试统一当前在大规模语言模型上的研究。
更具体地,我们设计了一个基于字符层面的卷积神经网络的 Softmax 损失函数。它的训练效率很高,其准确度也与完整的、含有多个数量级参数量的 Softmax 函数相当。
我们的研究在解决一个知名的大规模语言模型任务上,获得了前沿突破:对单个模型,perplexity 值从 51.3 减小为30.0,并使参数量减少了 20 倍。
我们展示了,一个含有多个不同模型的集和,其在这一任务上的 perpexity 值能够减小至 23.7,这对于当前水平来说是巨大的进步。
我们将模型和样本库开源,以帮助和激励更多的相关研究。
在第二章节里,我们谈论了语言建模的一些重要概念以及之前的一些研究。第三章节包含了我们对于神经语言建模领域的贡献,并强调了大范围递归神经网络训练的重要性。第四章节和第五章节详细描述了我们在项目中的经历和理解过程,并谈论了我们的方法与其它方法的关联。




















